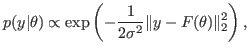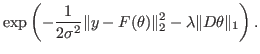Next: About this document ...
Johnathan M. Bardsley
Sampling from Bayesian Inverse Problems with L1-type Priors using Randomize-then-Optimize
Math Sciences
University of Montana
32 Campus Drive
bardsleyj@mso.umt.edu
Zheng Wang
Cui Tiangang
Youssef Marzouk
Antti Solonen
We focus on applications arising in inverse problems in which the
measurement model has the form
where 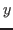 is the measurement vector;
is the measurement vector; 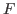 is the forward model function
with unknown parameters
is the forward model function
with unknown parameters 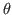 ; and
; and 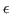 denotes independent and
identically distributed
Gaussian measurement error, i.e.,
denotes independent and
identically distributed
Gaussian measurement error, i.e.,
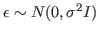 .
Then the probability density function for the measurements
given the
unknown parameters
is given by
.
Then the probability density function for the measurements
given the
unknown parameters
is given by
where `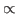 ' denotes proportionality. In Bayesian inverse problems,
one also assumes a prior probability density function
' denotes proportionality. In Bayesian inverse problems,
one also assumes a prior probability density function 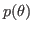 ,
which incorporates both prior knowledge and uncertainty about the unknown
parameters
. In this talk, we focus on the case in which
the prior
is of L1-type, i.e.,
,
which incorporates both prior knowledge and uncertainty about the unknown
parameters
. In this talk, we focus on the case in which
the prior
is of L1-type, i.e.,
Such priors include the total variation prior and the Besov
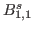 space priors.
With these two probability models (
space priors.
With these two probability models (
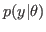 and
) in
hand, by Bayes' Law, the posterior density function has the form
and
) in
hand, by Bayes' Law, the posterior density function has the form
Regardless of the form of
,
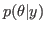 is non-Gaussian due to the
presence of the L1-norm. Moreover, in inverse problems,
is
high-dimensional. Taken together,
these challenges make the problem of sampling from
- which
is a requirement if one wants to perform uncertainty quantification -
difficult.
To overcome this, we extend the Randomize-then-Optimize (RTO) method,
which was recently developed for posterior sampling when
above is
nonlinear and
is Gaussian.
The extension of RTO to the L1-type prior case requires a variable
transformation, which turns
into a Gaussian probability
density
in the transformed variables, thus allowing for the application of RTO.
In this talk, we will begin by presenting the RTO method, and then its
extension to the L1-type prior case via the variable transformation.
Several numerical experiments will also be presented to illustrate the
approach and the resulting Markov Chain Monte Carlo method.
is non-Gaussian due to the
presence of the L1-norm. Moreover, in inverse problems,
is
high-dimensional. Taken together,
these challenges make the problem of sampling from
- which
is a requirement if one wants to perform uncertainty quantification -
difficult.
To overcome this, we extend the Randomize-then-Optimize (RTO) method,
which was recently developed for posterior sampling when
above is
nonlinear and
is Gaussian.
The extension of RTO to the L1-type prior case requires a variable
transformation, which turns
into a Gaussian probability
density
in the transformed variables, thus allowing for the application of RTO.
In this talk, we will begin by presenting the RTO method, and then its
extension to the L1-type prior case via the variable transformation.
Several numerical experiments will also be presented to illustrate the
approach and the resulting Markov Chain Monte Carlo method.
Next: About this document ...
root
2016-02-22